Content
part 1
- Introducing the conflict between informational and semiotic paradigms
- Peircean based pan semiotics
- The document mediating system
part 2
- The technological impetus for the development of information science
- LIS: The science of document-mediating systems
- The cognitive viewpoints opening toward a cybersemiotic concept of information in LIS
part 3
Figure 1 . Figure 2 . Figure 3 . Figure 4
Various types and definitions of information
There are various other different aspects of information and meaning that are significant. In his analysis, Buckland (1991: 6) usefully distinguishes the difference between:
a) Personal knowledge (private,
mental),
b) The process of knowing or becoming informed,
c) Objective/intersubjective materially registered knowledge (documents)
and
d) Information/data processing, the mechanical manipulation of signals
and symbols.
He summarizes this in Figure 3:
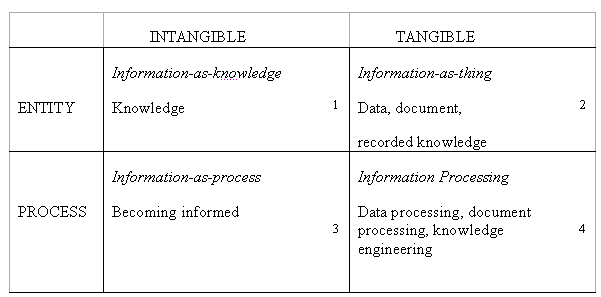
Figure 3:
Buckland’s matrix of different kinds of information (1991:
6) where he now used the information concept as an overall concept,
which will not be our strategy. [back]
I will use similar distinctions: 1. phenomenological knowledge, 2. documents, 3. cognition and 4. information processing. But not use information as an overall concept, but rather as a dualistic concept based on differences that has to be interpreted to generate meaning for an observer.
In my evaluation, the cognitive viewpoint represents an important first step away from the mechanistic information-processing paradigm in cognitive science as a foundation for LIS. It is a step towards a theory that encompasses the social and linguistic complexity of LIS and IR in a more realistic way. Librarians and LIS researchers know this complexity empirically from their own experience, and so far research has modeled different limited aspects of it. But we still have difficulties with the construction of a comprehensive theoretical framework, which can improve consistency in our use of scientific concepts within LIS, guide our research and development of research methods, and finally, provide the background for the interpretation of empirical research. The cognitive viewpoint has made some important changes in the basic view of the communication process in LIS and IR that are compatible with modern semiotics and pragmatic language philosophy. Within the cognitive viewpoint there has been empirical research and developed theory about the situation of the individual user with an information need confronting an information system. But further aspects must be developed for the theory to be comprehensive and broaden it into a general framework for information science.
As in Machlup’s theory of information, in the cognitive viewpoint the focus is on the individual. Machlup denies that social systems can communicate. Ingwersen (1996) is open to the study of the influence of knowledge domains on concept formation and interpretation as launched internationally by Hjørland & Albrechtsen (1995) in the domain analytic paradigm. They give theoretical reasons why classification and indexing should be directed toward the ways signification is created in discourse communities related to different knowledge domains, especially within the different fields of science.
This insight leads to the need for a general semiotic framework of communication and sign processing. We need to open LIS to the results and constructive thinking of a more general theory of how signs – such as words and symbols – acquire their meaning through communication, be it oral or written (Warner 1990). Semiotics should encompass not only social and cultural communication, but also should be able to address natural phenomena such as the communication of biological systems. It should have categories for technical information processing. At the same time, this trans-disciplinary theory should distinguish between physical, biological, mental-psychological and social-linguistic levels, and not reduce them to the same process of information. So far there is not much evidence that a profound and practical understanding of information and communication can be found by reducing them to the mechanical manipulation of symbols. A theoretical understanding of the interpretation of signs by biological-social systems is necessary for speaking about communication of information.
This leads us to the third requirement: a theory of the cognition and communication of signification should be able to encompass different types of systems. Neither the objective syntactic approach of the information-processing paradigm, nor the personal phenomenological approach of Machlup can deliver a framework encompassing communication processes in social, biological and technical systems. We cannot ignore that cybernetic information science that is behind and embedded in the computer is now a general tool for document mediating systems. As Buckland (1991) points out, we must draw on systems theory and cybernetics, and, with Warner and Blair, I add semiotics.
The usefulness of Peirce’s approach in LIS
This is all very abstract. Let us therefore consider its usefulness in the Library and information science area to demonstrate what this conceptualization does to help us in one sort of practice; one we have already introduced. The interpreting process according to the semiotic view is unfinishable, just as is scientific knowledge that seeks “the truth”. Peirce calls this unlimited semiosis. Signs are woven into meanings, which are linked to societal-cultural communicative praxis and history. Lexical denotations do not define the meaning of signs; these are defined by their use in social life, such as in a language game. Blair points out the significance for LIS for this fundamental understanding of the processes of signification:
In terms of inquiry, the notion of unlimited Semiosis has important consequences for the representation of texts. First of all, there can be no necessary and sufficient (i.e., complete) representation of a text (other than the entire text itself and even this may not be sufficient for retrieval purposes, (...)). Secondly, the standard to be used to judge the usefulness of a particular textual description is not that of “correctness,” but one of “appropriateness.” In other words, a textual description is neither correct nor incorrect, but, rather, more or less appropriate for a given task and situation. (Blair 1990: 137-138)
The compatibility between Blair’s “appropriateness” and Glasersfeld’s “viability” is obvious. Glasersfeld also thinks in terms of different tasks within society, which relates to the “work task/interest” of Ingwersen (1996) and the domains of Hjørland and Albrechtsen (1995). The meaning of words is created through language's cultural-historical background and the social communicative praxis between people, who have their own subjective historical access to the meanings of a sign. People are never in complete agreement about all the meanings of a word or concept. But through the development of customs they may reach an agreement on its meaning within situations experienced jointly. This is significant in various domains of science and the humanities, where long traditions have fixed the meaning of specific concepts. The practice of law has also developed its own special terminology. The pragmatic-semiotic approach is important because it is these connections that constitute the individual’s understanding and ability to:
1. Decipher the document’s signs.
2. Decipher the document as a sign in itself.
3. To evaluate the relation and value of the sign within the actual situation.
As Blair points out, one must base the organization of document-mediating systems on conventional uses of concepts:
In short, Peirce is pointing out that there can never be a necessary and sufficient explanation or description of the meaning of a sign/expression. In the sense of meaning which we have developed here, this means that there can never be a complete description of the kinds of allowable uses that can be made of a given expression. But this is not a despairing observation; in fact, it puts our analysis into a more thoughtful context. Instead of concerning ourselves with definitive uses of expressions, we can recognize this endless regression of meaning/signification and concentrate on elucidating conventional uses of expressions, realizing that new and creative uses of these expressions are inevitable …. What is important, then, is not just the uses of an expression, but the conventional uses of that expression in relation to some situation or task at hand. (Blair 1990: 137)
Peirce is both a phenomenalist and a realist. For Peirce, the meaning of a sign can be boiled down to the habits to which it gives rise and the influence it has on the world (including the inner biological and mental states of the interpretant) now and in the future. His theoretical rhetoric is the science of how signs become effective in a constantly changing historical and social context where there are no final referents. Blair (1990) draws the following conclusions for the understanding of indexing in LIS from this semiotic view of meaning:
In the first place, there is an unlimited number of unique documents which a single subject description can be used to represent. In the second place, there are an unlimited number of subject descriptions that reasonably could be applied to any one document. Traditional indexing theory, though aware of the ambiguity and inconsistency in the assignment of subject descriptions, has never demonstrated a full awareness of the magnitude of this problem, preferring to think of such difficulties as temporary aberrations rather than the first waves of a rising tide of difficulties (...). (Blair 1990: 169)
This provides a theoretical understanding of the enormous practical problems that have faced classificators and indexers for centuries. The ongoing evolution of signification poses a major difficulty for all document-mediating systems. Every classification system implicitly attempts to define specific meanings of words, and after a few years this becomes a problem for all dynamic knowledge systems. It is an essential for LIS to be able to change classification and indexing systems quickly to follow changes in the meanings of language, while at the same time keeping track of previous records. Since these changes are semantic and related to social practice, we do not yet have a mechanical way to accomplish this. Currently, any document database using words as classification and index terms should have its documents re-indexed every five years to keep in accordance with the present meaning of the words. Furthermore, it would be ideal to have specific classifications and indexing for different user groups with different interpretations of keywords, to account for their different types of educations, sciences, and practices.
Some would argue that Peirce’s semiotics do not tell us much about texts and language. But as Blair claims, Peirce is in general agreement with Wittgenstein, who in his “Philosophical Investigations” (1958) Sect. 43 says that: "For a large class of cases – though not for all – in which we employ the word ”meaning”, it can be defined thus: the meaning of a word is its use in the language. Suggests that the meaning of a word is equivalent to its use within a specific “language game” within a “life form” (Lebensform) as mentioned earlier? Language-games, forms of life and rule-following are shaping the meaning of any word. It is a matter of what we do with our language in social practice. It is not something hidden inside anyone’s mind or brain. Words, gestures, expressions come alive only within a language game, a culture, a form of life. If a picture for example means something then its meaning is not an objective property of the picture in the way that its size and shape are; it means something to somebody. The same goes for any mental picture. Mankind lives in cultural communities or forms of life, which are self-sustaining, self-legitimating, logically and normatively final. Actually Wittgenstein also mentioned being a Lion as a life form, when he explained that we could not understand it if it could talk.
Blair’s work attempts to integrate the crucial insights from Peirce’s semiotics with Wittgenstein's pragmatic language philosophy in order to re-examine the problems of IR and LIS in a new light. Blair argues that the semantic socio-pragmatic basis for meaning is a fundamental aspect of Peirce’s “unlimited semiosis.” Blair demonstrates how essential it is for LIS to realize that to comprehend a concept’s meaning, indexers and classifiers must understand its use for a given producer, in a given specific knowledge domain, and for a given user group. I suggest that this fundamental semiotic and socio-linguistic knowledge is the theoretical foundation behind the domain analysis of Hjørland and Albrechtsen (1995) as well as the cognitive viewpoint that employs concepts of “about-ness”.
But understanding the language game of the knowledge domain from which a document originates is not enough. One must also understand the language game of which the IR-process is a part. One aspect of this is the knowledge domain from which the user comes, but just as important are the intentions and social expectations users have of the system, as determined by their own understandings of their tasks. Blair writes:
Various kinds of activities (Forms of Life) can serve as a context for the retrieval of subject material. Activities such as defending or prosecuting a lawsuit, patent searching, conducting research, making a business decision, etc., all may make use of subject searching at various times and at various levels of intensity. The nature of the activity being pursued influences subject searching in two important ways: In the first place, the language of the activity, its jargon or cant, will determine which words will be used to describe and ask for subjects. Some activities have or use information that breaks down readily into subject areas, such as academic disciplines (especially the “harder” or more formal ones), while others have and use information that may not be as readily classifiable (think of activities that deal with new or innovative products or processes, such as new marketing, engineering or medical techniques, to name only a few). The other way in which the nature of an activity can influence retrieval is in determining the level of exhaustivity needed for satisfactory retrieval. Patent searching, the defense of a lawsuit, or searching to support original research all demand that the information retrieval which supports their activity be as exhaustive as possible. The activities of “Just keeping informed”, browsing, or introducing oneself to a new field require less exhaustive searches to be conducted. (Blair 1990: 158)
As we shall see, even more language games are actually in play in the IR-process, as is already understood by the cognitive viewpoint and its multiple uses of the concept of “about-ness” (Ingwersen 1992). In my opinion, the concept of a language game provides both a theoretical and pragmatic framework for understanding about-ness and provides an important link between this idea and broader social-pragmatic theories of language and cognition that are of importance for LIS.
Language games are not only connected to users’ searches for documents, but also with the overall design and maintenance of the system and the intentions behind the production of documents. Figure 4 illustrates some of the language game systems involved in IR for a document-mediating system.
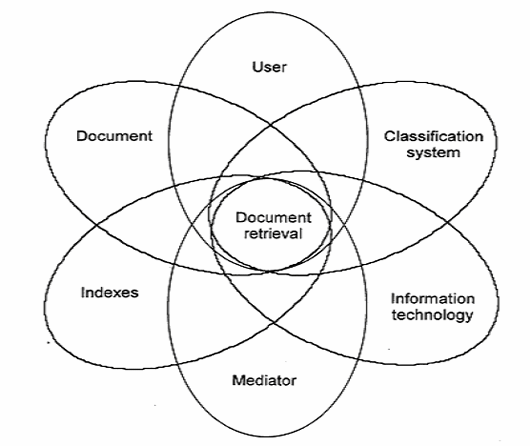
Figure 4:
The different language games involved in IR for a document-mediating
system. A substantial part of the challenges facing LIS are
not so much technical difficulties as socio-linguistic difficulties
of making concepts communicate within and across different types
of language games. The user has his own language game, but also
must handle documents with a language game of their own determined
by their authors, ordered by the language game of a classification
system, indexed according to the language game of the indexer,
and searched for in the language game of the search language.
If the user has someone to help, then this problem will be further
interpreted through the language game of the mediator (often
that of the librarian or documentalist). [back]
The skill of the librarian to mediate between different language games in document mediation is a complicated one that becomes increasingly complex every year. Because the number of documents and users grows exponentially, economic considerations force us to seek automated solutions to these problems. It is very important to research how to achieve the most productive integration between machine and human skills. But the economic necessity of using machines should not obscure the fact that the central challenges facing LIS are often the interface between the socio-pragmatic linguistic and the logic or algorithmic processing of sign vehicles that computers perform.
Indexing is central for information storage and retrieval. The indexer allows a descriptor to represent something else – such as a document – so that it can be found by means of something else, on the basis that these entities in some respect share the same content/idea. This description parallels the description of the sign.
It is necessary to identify the sign relations between descriptors and documents to understand these relations as signs, and to recognize that the signs can alter sign categories – in other words, the sign alters nature according to the person who interprets it. The relation between the descriptor and the document is essential for understanding and recognizing what happens during indexing and retrieval. Through a semiotic discussion of this relationship is it possible to describe the nature of descriptors from the users’ level of knowledge. We have included the user in the descriptor-document relation. However, we have seen that there are also other semiotic webs involved in the user-descriptor-document relationship – namely the semiotic webs of the indexers and the semiotic webs of the authors. If information retrieval is to be successful, these semiotic webs must approximate each other.
I am sympathetic to van Rijsbergen and other colleagues’ attempts to resolve the difficulties of computer document mediation by creating new kinds of logics, although I would still argue that the core relationship for mediating documents is semantic, and that semantic relationships are not built primarily on logic, but rather on motivated relations influencing the intentionality of conscious awareness. These are established through the evolution of living systems (ethology) and through the history of life forms and language games in societies. They are created as structural couplings of significance within a semiotic web (such as Peirce’s triadic semiotics), established through the living system’s relationships to nature and other bodies within social systems.
The computer has seduced us into framing our questions within its algorithms. It seems we have forgotten to maintain and develop a theoretical framework for our subject area that allows us to see beyond the horizon of the computer and to make demands of those researchers developing computer systems. If we do not provide a metatheoretical description of our own area, it becomes difficult for others, such as computer scientists and software developers, to understand that they have entered a new territory with different rules. We must provide a strong theoretical understanding of the difference between physical and intellectual access. The growth of the Internet makes this knowledge more important every day.
One should start with a pragmatic analysis of the informal communication system. This is the most powerful semiotic force to which any information system must adapt, and as Lakoff (1987) demonstrates, its semantic patterns are neither logical nor random – they are motivated. This accords with the cybernetic view of information as generated within an autopoietic system, and language communication as occurring within generalized media. Motivation stems from the type of media, but the actual language game chosen within the media determines a large part of the motivation for the relationship between concepts. If there is no proper feedback between producers, indexers, and users, the system will not produce information – it will not fulfill our expectations. We all participate in several language games simultaneously, but professionally we must consciously select and maintain one at a time whenever possible. As information is only potential when there is no interpretant, the only information in our systems is relevant retrieved documents. This further supports much of Bates’ work on the sense-making approach (1989).
The pragmatic approach generally means, as previously mentioned, that a philosophy of science analysis of the domains/subject area/work tasks and paradigms in science, as well as a knowledge sociological analysis of communication patterns such as the discourse analysis of written text, is important for describing the decisive context of the use of our systems. They must be adjusted to our context, work task, and the budget allotted the research. These methods should be supplemented by questionnaires, association tests, and registration methods. The expenses of this research are a challenge, but the willingness to pay for basic research is connected to the users’ awareness of how central insights into the socio-pragmatic linguistic framework are to the performance of the designed systems. We are moving past the phase of unreflective fascination with electronic systems and into a more realistic evaluation of how they can help us mediate communications between humans via documents. If one considers Ingwersen’s (1992) analysis of what a mediator system must do to function properly, one realizes we cannot expect machines to solve the complexity of human communication without human mediation.
This knowledge also tells us that there is limited utility to the non-professional users of the enormous scientific and technical bibliographic bases where many millions of documents have been categorized into Boolean systems by trained documentalists. Here, the users are the documentalists themselves, and the trained researchers from part of the domain, search bases that have not been made generally accessible through the Internet. New digital libraries based on the same outdated principles and word-to-word matches are constantly being established also in the industry. A bibliographic system such as BIOSIS, based on the present theory, will only truly function within a community of biologists. This means that both the producers and the users must be biologists – and so must the indexers. Even then there will be difficulties, because the producers and the users of the bibliographic database will also be researchers. This is a life form that follows a language game different from that of indexers. But if indexers maintain contact with both users and producers, solicit their feedback, attend their conferences, and investigate their ways of utilizing literature and scientific concepts, the system will holistically produce information. One should not understand document-mediating systems as merely information keepers and deliverers. They are information producers, once we include interactions with users as part of the system!
In the enormous domain-specific systems, we have to accept a centrally organized knowledge system. We can simplify through menu-driven systems only at the cost of speed and precision. We can help users understand what kind of system they are working with by providing thesauri to consult and work from directly. We can remind them to consider specific vital details by asking them to answer questions as part of an obligatory procedure. All this is now done in new types of interfaces. Blair (1990) suggests offering users the opportunity to view extracts of papers that the use of specific index terms will access, and what other users have accessed using similar searches. Any technique that helps users understand the language game they are participating in, how it is structured, and how words work within it is fruitful when combined with opportunities to navigate, explore, and learn the system by oneself.
In these cases we cannot bring the system to the user, so we must bring the user to the system. This will not happen if we simply install a natural language processing interface that pretend to the users that this system will do most of the thinking for them. We should clarify that these systems only help users who do not have the time or ability for other types of search process, because users will have practically no control over the processes by which papers are accessed. This might nevertheless be useful if these users want only a few documents on a subject of interest. The same can be said for the automatic indexing of full-text documents (Blair 1990), unless it is in a sharply delineated and rigidly formalized subject area. Automated procedures give users little insight into what occurs within a system. Users have very little opportunity to control the language game they are participating in. This does not even broach the issues that arise when index terms from one language game are used to seek documents in another.
The problem of intellectual access cannot be resolved by intelligent user-interfaces in the pre-existing Boolean system. Nor will the addition of automated indexing, including natural or knowledge-domain specific language manipulation, or including full text systems (Blair 1990). Undoubtedly each is useful within limited contexts. In currently existing, large scientific bibliographic databases, considerable efforts have been made to deliver interfaces that obligate users to pay attention how the base is structured and remember its most relevant aspects. By reading manuals, one can acquire a simplified theoretical impression of how the controlled index terms are used. Blair (1990) suggests that users should have the opportunity to view samples of papers that are retrieved using a search term, so that users can gain experience about how words function within the language game of the classification system, and through this learn their meanings. The BIOSIS Previews manual, for example, gives theoretical examples of this kind. It is also important to allow as much opportunity for exploring as possible.
When we contemplate designing a new document-mediating system from the bottom up, the suggestion is to specialize document-mediating systems for specific knowledge domains, knowledge levels, and points of interest, and to consider the size of the system. This means constructing bases entirely from users’ needs and conceptual worlds. We must supplement current methods with pragmatic analysis of discourse communities with various knowledge domains, both scientific and non-scientific.
Most current bibliographic databases contain documents produced by different paradigms, specialties, and subject areas, all of which have different language games even when they share a vocabulary. I only need to mention how data-engineers, cognitive psychologists, and information scientists use the concept of information, or how Newtonian physics and Einstein’s general relativity use the concept of space. Each subject area with interest in the documents of a database should have these documents indexed according to their own language game in order to make precise searches possible. As is already acknowledged in BIOSIS, for example, chemists, physicians, and biologists each have specific terms for chemicals, illnesses, and classifications of plants and animals that are respected by the BIOSIS indexing procedure. But under current indexes, as a biologist I must use chemical notation searching for a chemical, and chemists must use the correct biological name for a plant to find articles about a chemical substance it produces. Not addressed are those words common to all three subject areas, but that has different meanings because they are part of different language games. We must develop methods to more fully analyze the discourse communities in various knowledge domains, scientific and non-scientific, theoretical and practical. We must get a firmer grasp on the social-pragmatic connotations of words and concepts in order to integrate them into the semantics of semiotic nets as a basis for thesaurus building.
As a result, one of the large research areas of LIS is how to integrate bibliographic databases and full-text databases into different domains, organizations, interests, and levels in organization. This demands that one to distinguish and characterize different domains, levels, and language games in, for instance, an organization. In addition to the methods already employed by LIS, these analyses will benefit from methods derived from discourse and conversation analysis, as well as from socio- and ethnolinguistic empirical analysis of cultural communication.
Bøgh Andersen (1990) delivers a semiotic framework for a computer semiotics and some applicable methods from a non-LIS context. Most fields today are, at least to some degree, interdisciplinary – BIOSIS is a good example, as it is relevant to medicine, chemistry, and the behavioral sciences – and one could for imagine that eventually interest groups from different domains would develop their own systems for indexing documents, so they can chose their own point of entry to these systems. In addition, there will be various offers to visualize systems and their language games aimed at searchers who lack domain knowledge or technical search knowledge, combined with many possibilities for navigation. But that is a far cry from what users want.
What is it many of us want? Well I want the document based to be like the way I organize the books in my office. I would like to be able to put in my electronic knowledge profile, build up over my entire life. When I load that into the system I want all the books re-indexed according to the way I define the groups and index words according to my understanding and use of the concepts.
Further, I think most of us do not put them in alphabetic order after writer or title in our offices if we have more than 100 books there, but tend to group them according to various subject areas, which are again more defined from the way we use them – for instance in teaching various courses or participating in various research groups or projects – than from some international definition of the area. Thus the ultimate wish of a user of a database is that all documents with only a moments notice are related to his or hers own personal knowledge profile. The wish of the database designer has always been to construct the perfect universal system that all users had to learn. Thus as in the sciences and as in the discussion about rationality in our culture we are torn between those striving towards the universal truth and those who strive for meaning be it individually, culturally or even universal.
One of our civilizations great works
on that is Gadamer, Truth and Method, which develops the hermeneutic
view in a reflection also on the truth and method concepts in the
sciences. Peirce’s semiotics can be seen as a transdisciplinary
paradigm that also includes phenomenology and hermeneutics.
Barbieri, M.(2001): The organic Codes: The birth of Semantic Biology, PeQuod.
Bates, M. J. (1989): The design of browsing and berry-picking techniques for the online search interface, Online Review, Vol. 13, No. 5, pp. 407-424.
Bateson, G. (1973): Steps to an ecology of mind, Paladin, USA, Great Britain.
Blair, D.C. (1990): Language and representation in information retrieval. Amsterdam: Elsevier.
Buckland, M. (1991): Information and Information Systems, New York; London: Greenwood.
Bøgh Andersen, P. (1990): A theory of computer semiotics: semiotic approaches to construction and assessment to computer systems. Cambridge: Cambridge University Press.
Fodor, J. A. (1987): Psychosemantics: the Problems of Meaning, Cambridge, MA: MIT Press.
Foerster, H. von (1980): Epistemology of communication, in Woodward, K (ed): The Myth of Information: Technology and Postindustrial Culture. London: Routledge & Kegan Paul.
Gadamer, H.-G. (1975): Truth and Method, New York: Seabury Press.
Hayles, N.K. (1999): How we became posthuman: Virtual bodies in cybernetics, literature, and informatics, The University of Chicago press, Chicago and London.
Hjørland, B. & Albrechtsen, H. (1995): Toward A New Horizon in Information Science: domain Analysis, Journal of the American Society for Information Science. Vol. 46, No. 6. pp. 400-425.
Hoffmeyer, J. and Emmeche, C. (1991): Code-Duality and the Semiotics of Nature, in M. Anderson and F. Merrell (ed): On Scientific Modeling, New York: De Gruyter, pp. 117-166.
Ingwersen, P. (1992): Information Retrieval Interaction. London: Taylor Graham, pp. 246.
Ingwersen, P. (1996): Cognitive Perspectives of Information Retrieval Interaction: Elements of a Cognitive IR Theory, Journal of Documentation, Vol. 52, No. 1, March 1996, pp. 3-50.
Kuhn, T. (1970): The Structure of Scientific Revolutions, 2nd enlarged ed. Chicago: The University of Chicago Press.
Lakoff, G. (1987): Women, Fire and Dangerous Things: What Categories Reveal about the Mind, Chicago and London: The University of Chicago Press.
Luhmann, N. (1995): Social Systems. Stanford, CA: Stanford University Press.
Machlup, F. (1983): Semantic Quirks in Studies of Information, in Machlup, F. & Mansfield, U.: The study of information: interdisciplinary messages, New York: John Wiley & Sons. pp. 641-671.
Maturana, H & Varela, F. (1980). Autopoiesis and Cognition: The realization of the Living, London: Reidel.
Nöth, W. (1995): Handbook of Semiotics. Bloomington and Indianapolis: Indiana University Press.
Peirce, C.S. (1994 [1866-1913]): The Collected Papers of Charles Sanders Peirce. Electronic edition reproducing Vols. I-VI ed. Charles Hartshorne & Paul Weiss (Cambridge: Harvard University Press, 1931-1935), Vols. VII-VIII ed. Arthur W. Burks (same publisher, 1958). Charlottesville: Intelex Corporation.
Prigogine, I. & Stengers, I. (1984). Order Out of Chaos: Man's New Dialogue with Nature, New York: Bantam Books.
Schrödinger, E. (1967). What is life? The physical aspect of the living cell and mind and matter, Cambridge: Cambridge University Press.
Searle, J. (1989): Minds, Brains and Science. London: Penguin Books.
Shannon, C. E. & Weaver, W. (1969): The Mathematical Theory of Communication, Urbana: The University of Illinois Press.
Warner, J. (1990): Semiotics, Information Science and Computers, Journal of Documentation, Vol. 46, No.1, pp. 16-32.
Warner, J. (1994): From Writing to Computers. London: Routledge.
Vickery, A. & Vickery, B. (1988): Information Science - Theory and Practice, London: Bowker-Saur.
Winograd, T. & Flores, F (1986): Understanding computers and cognition: a new foundation for design, Norwood, N.J.: Ablex Pub. Corp.
Søren Brier ist Associate Professor im Bereich philosophy of information, cognition and communication sciences an der CBS (Copenhagen Business School).
Unter anderem ist er Herausgeber der Zeitschrift Cybernetic & Human Knowing: A Journal of Second Order Cybernetics, Autopoiesis and Cybersemiotics.
http://www.imprint.co.uk/C&HK/cyber.htm
Homepage: http://uk.cbs.dk/content/view/full/9710